 一、H100 GPU:800亿晶体管、六大创新
一、H100 GPU:800亿晶体管、六大创新
每次英伟达的GPU新架构都会以一位科学家的名字来命名,这次同样如此。
新Hopper架构的命名取自美国计算机科学家格蕾丝·赫柏,她是耶鲁大学第一位数学女博士、世界上第三位程序员、全球首个编译器的发明者,也是第一个发现“bug”的人。

格蕾丝·赫柏正在教学COBOL编程语言
1945年9月9日,格蕾丝使用的Mark Ⅱ机出现故障,经过近一天的排查,她找到了故障的原因:继电器中有一只死掉的蛾子。后来,“bug”和“debug”这两个词汇就作为计算机领域的专用词汇流传至今。
基于Hopper架构的一系列AI计算新品,被冠上各种“全球首款”。按行业惯例,但凡比较AI算力,必会拿英伟达最新旗舰GPU作为衡量标准。
英伟达也不例外,先“碾压”一下自己两年前发布的上一代A100 GPU。
作为全球首款基于Hopper架构的GPU,英伟达 H100接过为加速AI和高性能计算扛旗的重任,FP64、TF32、FP16精度下AI性能都达到A100的3倍。

可以看到,NVIDIA越来越热衷于走稀疏化路线。过去六年,英伟达相继研发了使用FP32、FP16进行训练的技术。此次H100的性能介绍又出现了新的Tensor处理格式FP8,而FP8精度下的AI性能可达到4PFLOPS,约为A100 FP16的6倍。
从技术进展来看,H100有6项突破性创新:
1. 先进芯片:H100采用台积电4N工艺、台积电CoWoS 2.5D封装,有800亿个晶体管,搭载了HBM3显存,可实现近5TB/s的外部互联带宽。
H100是首款支持PCIe 5.0的GPU,也是首款采用HBM3标准的GPU,单个H100可支持40Tb/s的IO带宽,实现3TB/s的显存带宽。黄仁勋说,20块H100 GPU便可承托相当于全球互联网的流量。
2. 新Transformer引擎:该引擎将新的Tensor Core与能使用FP8和FP16数字格式的软件结合,动态处理Transformer网络的各个层,在不影响准确性的情况下,可将Transformer模型的训练时间从数周缩短至几天。
3. 第二代安全多实例GPU:MIG技术支持将单个GPU分为7个更小且完全独立的实例,以处理不同类型的作业,为每个GPU实例提供安全的多租户配置。H100能托管7个云租户,而A100仅能托管1个,也就是将MIG的部分能力扩展了7倍。每个H100实例的性能相当于两个完整的英伟达云推理T4 GPU。
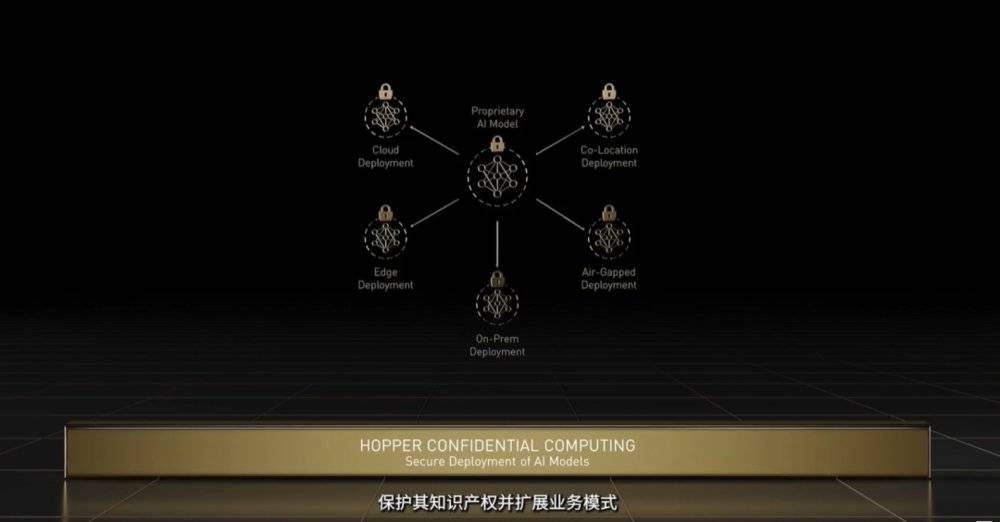
4. 机密计算:H100是全球首款具有机密计算功能的GPU加速器,能保护AI模型和正在处理的客户数据,可以应用在医疗健康和金融服务等隐私敏感型行业的联邦学习,以及共享云基础设施。
5. 第4代英伟达NVLink:为了加速大型AI模型,NVLink结合全新外接NVLink Switch,可将NVLink扩展为服务器间的互联网络,最多连接多达256个H100 GPU,相较于上一代采用英伟达 HDR Quantum InfiniBand网络,带宽高出9倍。
6. DPX指令:Hopper引入了一组名为DPX的新指令集,DPX可加速动态编程算法,解决路径优化、基因组学等算法优化问题,与CPU和上一代GPU相比,其速度提升分别可达40倍和7倍。
总体来说,H100的这些技术优化,将对跑深度推荐系统、大型AI语言模型、基因组学、复杂数字孪生、气候科学等任务的效率提升非常明显。
比如,用H100支持聊天机器人使用的monolithic Transformer语言模型Megatron 530B,吞吐量比上一代产品高出30倍,同时能满足实时对话式AI所需的次秒级延迟。
再比如用H100训练包含3950亿个参数的混合专家模型,训练速度可加速高达9倍,训练时间从几周缩短到几天。

H100将提供SXM和PCIe两种规格,可满足各种服务器设计需求。
其中H100 SXM提供4 GPU和8 GPU配置的HGX H100服务器主板;H100 PCIe通过NVLink连接两块GPU,相较PCIe 5.0可提供7倍以上的带宽。PCIe规格便于集成到现有的数据中心基础设施中。
这两种规格的电力需求都大幅增长。H100 SXM版的散热设计功耗达到700W,比A100的400W高出75%。据黄仁勋介绍,H100采用风冷和液冷设计。

这款产品预计于今年晚些时候全面发售。阿里云、AWS、百度智能云、谷歌云、微软Azure、Oracle Cloud、腾讯云和火山引擎等云服务商均计划推出基于H100的实例。
为了将Hopper的强大算力引入主流服务器,英伟达推出了全新的融合加速器H100 CNX。它将网络与GPU直接相连,耦合H100 GPU与英伟达ConnectX-7 400Gb/s InfiniBand和以太网智能网卡,使网络数据通过DMA以50GB/s的速度直接传输到H100,能够避免带宽瓶颈,为I/O密集型应用提供更强劲的性能。

| 





 2022-03-23 16:22:59
2022-03-23 16:22:59

